Bimodal Speech Recognition
Overview
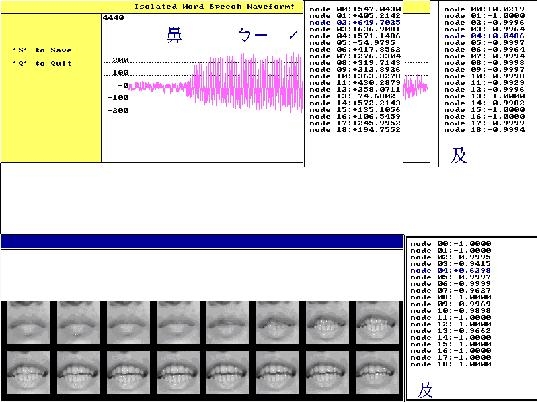
The goal of bimodal speech recognition is to
combine audio and visual information to enhance speech recognition rate under
poor audio conditions (noise or acoustically confusing words). A lipreading
system recognizes a spoken word based on the input lip motion. To handle this
problem, we proposed a space-time delay neural network that can automatically
discover the features embedded in spatiotemporal domain in the training process
and use these features to classify different lip motions. Our experimental
results indicated that, using only lip motion video, the lipreading system can
achieve a 77.8%~90% recognition rate for Chinese digits, and 44.7%~48.9%
recognition rate for nineteen Chinese confusing words.
We also implemented an on-line bimodal speech
recognition system to test how lipreading can improve the audio speech
recognition. The recognition system consisting of three DSP processors and one
Pentium processor concurrently processes lip motion video and speech signals.
The whole recognition process, including mouth region centering, 2D-FFT, speech
feature extraction, neural network computation, HMM computation, and decision
fusion, can be executed in real time.
Publication
·
Chin-Teng Lin, Hsi-Wen Nein and Wen-Chieh Lin, “A
Space-Time Delay Neural Network for Motion Recognition and Its Application to
Lipreading, ” International Journal of Neural Systems, Vol. 9, No. 4, Aug
1999, pp. 311-334.
·
Wen-Chieh Lin, A Space-Time Delay Neural
Network for Motion Recognition and Its Application to Lipreading in Bimodal
Speech Recognition, Master thesis, National Chiao-Tung University, Taiwan,
1996.
·
Wen-Chieh Lin, Hsi-Wen Nein, and Shin-Hui Liang, A DSP-based On-line Bimodal Speech Recognition System,
First Prize of the Graduate Student Team in the Texas Instrument DSP Design
Challenge, Taiwan, 1996.